Data Import Configuration
You can import files up to 500 MB using an FTP or file connection.
Enter information into the fields.
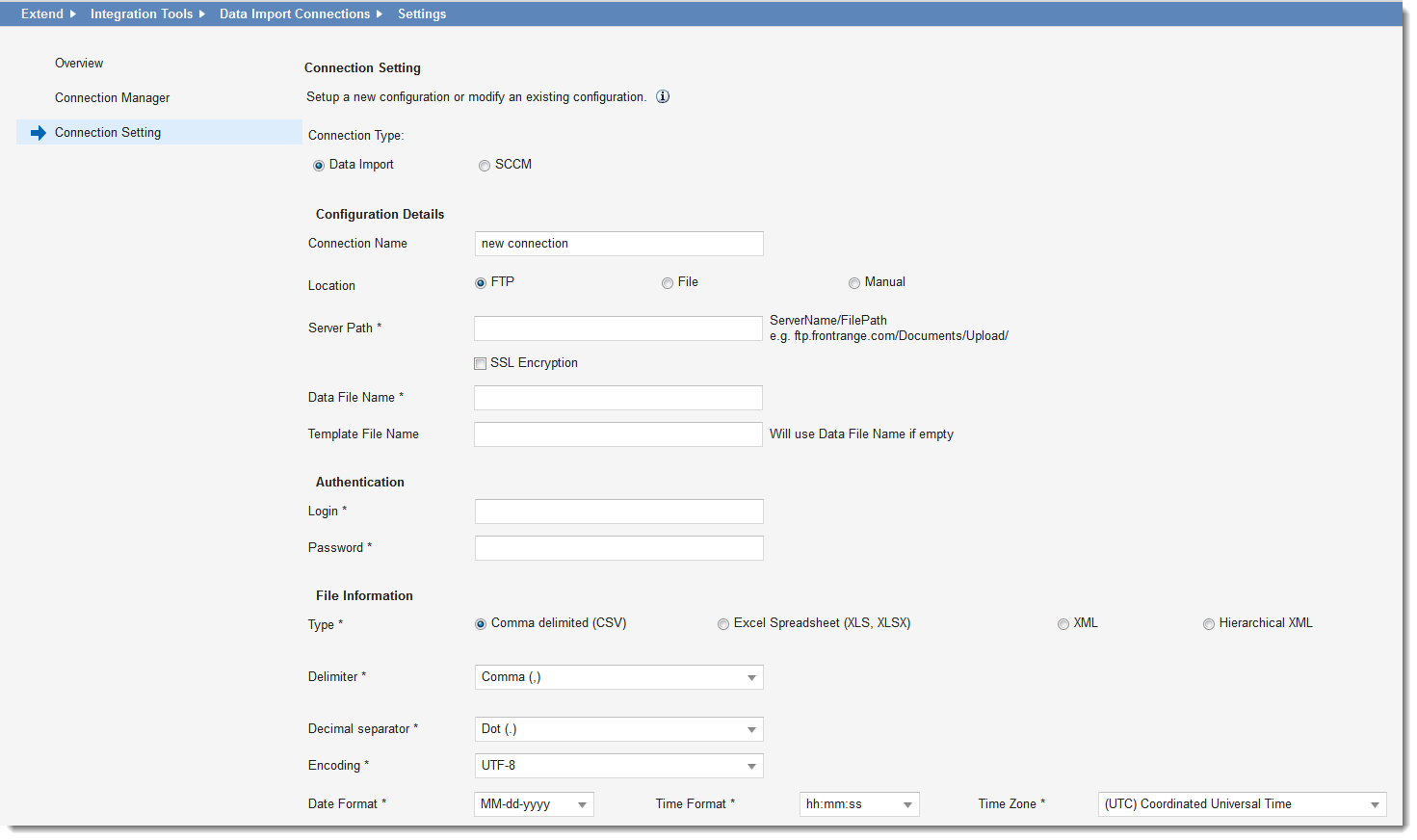
Data Import Connection Settings
| Field | Description |
|---|---|
|
Connection Name |
A unique name for the connection. |
To import a file from the network (with VPN access) or from an FTP site, ensure that you have the necessary permissions to access the file. Select one of the following options:
Select this option to connect to a file server (not a web server) to transfer data. The FTP protocol is used to upload files from a workstation to a specified FTP server.
| Field | Description |
|---|---|
| Server Path | The server path as FTPServername/Filepath. Be sure to use a backslash (/). Do not include the name of the file. |
| SSL Encryption | Engages SSL encryption. |
| Data File Name | The name of the data file. |
| Template File Name | Optional. Enter the name of the file that is a subset of the mapping file. If your mapping file is large, you might want to create a smaller file containing only the columns or fields for mapping - to create a map before data import. |
| Login | The user name used to access the server. |
| Password | The password used to access the server. |
Select this option to import data from a shared network file.
| Field | Description |
|---|---|
| Server Path | The server path, such as Servername\Filepath. VPN access is required when HEAT accesses the hosting server. When using Servername instead of an IP address, ensure that the IP address is known to HEAT. Be sure to use a forward slash (\). Do not include the name of the file. |
| Data File Name | The name of the data file. To import multiple files, see Import Multiple Files. |
| Template File Name | Optional. Enter the name of the file that is a subset of the mapping file. If your mapping file is large, you might want to create a smaller file containing only the columns or fields for mapping - to create a map before data import. |
| Login | The user name used to access the server. |
| Password | The password used to access the server. |
Select this option to create a non-scheduled one-time data import.
You can import data from a local file source into your database. This import configuration can be saved to your list of integration connections, but can not be scheduled, due to the nature of a manual import. You must manually import the data file each time you run the connection.
| Field | Description |
|---|---|
| Data File Name | The name of the data file. |
Select the file type to import.

|
Line breaks are supported in XML and Microsoft Excel files, but not in CSV files. |
This format can be read by most applications, such as Microsoft Word or Microsoft Excel.
| Field | Description |
|---|---|
| Delimiter |
This field appears when you select Comma Delimited Type. Enter the field delimiter (for example, #), or choose an option from the drop-down list:
|
| Decimal separator | The decimal separator symbol. Enter a value or choose one from the drop-down list. |
| Encoding | The character standard of your file. Select from the drop-down list. |
|
Date Format Time Format Timezone |
The date, time, and time zone format of your file. Select values from the drop-down lists. This ensures that your data is imported correctly into the database. If your data does not contain date or time fields, use the default settings. |
This format can be read by Microsoft Excel or other compatible applications. You can only import a single-page Microsoft Excel worksheet.
| Field | Description |
|---|---|
| Decimal separator | The decimal separator symbol. Enter a value or choose one from the drop-down list. |
| Encoding | The character standard of your file. Select from the drop-down list. |
|
Date Format Time Format Timezone |
The date, time, and time zone format of your file. Select values from the drop-down lists. This ensures that your data is imported correctly into the database. If your data does not contain date or time fields, use the default settings. |
Add a Role column to the input file that contains the role display names. If you are updating an existing employee record during the upload, any new roles are added to the roles already assigned to the employee in the employee record. The system separates roles by commas.
|
|
The Role column should be named *Role* (with the asterisks included) and should include the role display name and not the actual role name. For example, include Self Service and not SelfService. All role names should be in the column and separated by commas. |
- No AddRoleBehavior setting in the configuration file.
-
By default, it is always “merge” behavior.
Select to import generic XML data.
| Field | Description |
|---|---|
| Table Element | The name of the table object. |
| Row Element | The name of the row object. |
| Include Header Row |
Inputs an XML file in legacy GBU format. In this format, the Table Element is "Rows", and Row Element is "Row".
<Rows>
Do not check this option to use the flexible two-level format. In this example,the Table Element is "Employee_Info", and Row Element is "Employee". The field names for this "Employee" object can be an element (such as Name) or a row-level attribute (such as Employee_Number).
<Employee_Info xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:noNamespaceSchemaLocation="employee.xs"> <Employee Employee_Number="105"> <Name>Masashi Okamura</Name> <Department>Design Department</Department> ... </Employee>
|
| Decimal separator | The decimal separator symbol. Enter a value or choose one from the drop-down list. |
| Encoding | The character standard of your file. Select from the drop-down list. |
|
Date Format Time Format Timezone |
The date, time, and time zone format of your file. Select values from the drop-down lists. This ensures that your data is imported correctly into the database. If your data does not contain date or time fields, use the default settings. |
Data with null values do not appear in the XML file, which can cause problems when exporting data.
For example, consider the following XML. Note the data for the second employee contains an email cell with no attributes. This cause the data to import incorrectly.
<Employee_Info>
<Employee Employee_Number="105">
<Name>Masashi Okamura</Name>
<Department>Design Department</Department>
<Email>masashi@design.com</Email>
<Phone>408.555.1234</Phone>
</Employee>
<Employee Employee_Number="106">
<Name>Frank Smith</Name>
<Department>Design Department</Department>
<Email></Email>
<Phone>408.555.1235</Phone>
</Employee>
</Employee_Info>
To alleviate this issue, create an empty string:
<Employee_Info>
<Employee Employee_Number="105">
<Name>Masashi Okamura</Name>
<Department>Design Department</Department>
<Email>masashi@design.com</Email>
<Phone>408.555.1234</Phone>
</Employee>
<Employee Employee_Number="106">
<Name>Frank Smith</Name>
<Department>Design Department</Department>
<Email>""</Email>
<Phone>408.555.1235</Phone>
</Employee>
</Employee_Info>
Select to import a structured XML file.
| Field | Description |
|---|---|
|
Table Element Row Element Include Header Row |
These options are disabled because the values are automatically picked up by the XML file. |
| XSLT | Optional. Defines a template to apply to your XML file. Click Upload and navigate to your template file. |
| Decimal separator | The decimal separator symbol. Enter a value or choose one from the drop-down list. |
| Encoding | The character standard of your file. Select from the drop-down list. |
|
Date Format Time Format Timezone |
The date, time, and time zone format of your file. Select values from the drop-down lists. This ensures that your data is imported correctly into the database. If your data does not contain date or time fields, use the default settings. |
See also About Hierarchical XML Format.
|
|
Large files (over 50 MB) take longer to preview, because the entire file is downloaded before the first batch can be shown. In other types, the copy/download occurs when moving from the Connection to the Object Mapping page. In Hierarchical XML, we bypass ALL mapping pages. Hence, the copy/download only occurs when a user wants to preview the file. |
To import multiple files, you can use the asterisk wild card in the Data File Prefix field. For example, if you enter Test*.csv, all csv files beginning with Test are imported.
If you have the following files, for example:
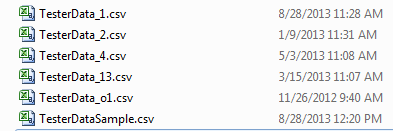
- Files are processed based on the their Creation DateTime, so TesterData_o1.csv is processed first, although alphabetically it is fifth, and TesterData_1.csv is processed fifth, although it is first alphabetically.
- A Processed folder is created in the path if it does not exist. For this example, it is \\CA-L02540\test\Processed\. As each file is imported, it is moved to the Processed folder. S When the import is complete, all six files above will be moved from the \test folder into the \test\Processed folder.
- As each file is processed, the Integration History – Source Name column is updated by appending each processed file name, so it will be
- TesterData_1.csv
Then
- TesterData_2.csv,
- TesterData_3.csv
And so on …
Click Test Connection.
If your connection is set up correctly, a Success confirmation message appears. Notice that the connection date and time are updated.
If the connection fails, do not click Next until Test Connection shows the Success message. The connection could fail because of various reasons such as incorrect authentication, restricted or no FTP access, or restricted file permissions.
- Click Next.
Enter information into the fields.
| Field | Description |
|---|---|
| Mapping | The mapping. Select the default mapping or select Add New from the drop-down list. |
| Name |
The mapping name. Use the default name, modify the name, or choose Add New from the drop-down list to create a new mapping. To modify the existing name, click Save as New. A clone of the mapping is created, which you can then modify. This button is only enabled when an existing mapping is selected. |
| Max file size | Read only. Shows the maximum file size that you can import. The default maximum file size is 250 MB. |
| Source File Name | Read only. Taken from the value in the File Name field. |
| Source Unique Key | Lists the fields containing the keys that uniquely identify your record. The fields that appear in the list are taken from the first record in your source file. Choose the field that is primary in identifying your records. |
| Target Business Object |
The primary business object in HEAT into which the data is imported. This list shows all the business objects in HEAT. You can enter a few letters of the target business object and then click Filter by Name or Filter by Object to narrow your search. For example, if you are importing a list of employee records into HEAT, the primary business object you need to map to is Profile#Employee. |
After mapping the object tables to query, specify filter conditions for the root business object.
- Click Create Filter. The filter fields appear.
|
|
If the Create Filter button is not visible, delete the default mappings on the previous page. |
- Select the condition that you want and enter the fields and operators into the form.
Filter Manager Conditions and Fields
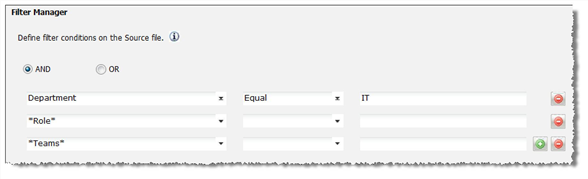
- Click Add to add another row.
Define the field level mapping and transformation.
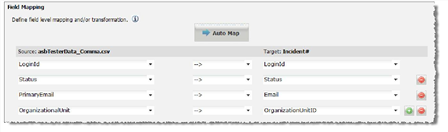
- The left column shows the source file name and the right column shows the target business object field name.
- If appropriate, select a transformation function from the middle column.
- Select the field names to map between the source file and the target object in HEAT.
--or--
- Click Auto Map to map the source file column header to the target field name.
|
|
Remapping the source column header does not change your existing mapping. |
See Field Mapping for more information.
Mapping Files with Currency Data
To prevent errors while importing files containing currency data, map the currency value and the currency type separately.
For example, if your file contains a value such as NNN.NN GBP (eg. 8999.00 GBP), create a column for the numeric value (NNN.NN) and another column for the currency type (GBP).
If that is not practical, then you can use the Split function on the Field Mapping page:
"Currency", , 0 - Split - "Currency"
"Currency", , 1 - Split - "Currency_Currency"
See Schedule Manager on how to create a scheduled import.